A Slacker’s Guide to Programming

Predicting Singapore Pools 4d Lottery winning numbers with Machine Learning
Who wants to be a millionaire?
TL;DR
Introduction
My good buddy, Ah Seng, approach me with a strange request the other day.
It started from this forum thread on Hardwarezone.
Apparently, the subject, Ms Foyce Le Xuan, could predict winning 4d lottery combinations.
She posted proof of the winnings on her Instagram account week after week.

There was much debate in the forum on the strategies she used to maintain her consistent winning streak.
Although there were contrasting views with regards to her methods, the strong consensus was that she had a piece of "magical software".
A programming tool that could generate winning lottery combinations using specialised algorithms.
The Bet
"Oei Terence, if we could get historical data of past winning 4d numbers, I am pretty sure we could build something similar leh!", said Ah Seng.
I was adamant that winning lottery numbers are random events.
If people could devise algorithms to predict future winning numbers using past patterns, it would be all over the news.
Nevertheless, I was keen to disprove his hypothesis.
Machine Learning or Learning Machine?
Using historical data to predict future events sounded like some CSI "zoom and enhance" AI Technology.
I had no prior knowledge about the obscure field of data science.
Thankfully, there are tons of machine learning resources available online.
The one offered by Google was pretty good - Machine Learning Crash Course.
The Tensorflow website provides extensive resource and documentation as well.
That being said, this exploration into the world of machine learning was definitely not a walk in the park for me.
This exploration into the world of machine learning was definitely not a walk in the park for me.
Requirements
- Python 3
- Selenium
- PhantomJS
- Chrome Webdriver
- Beautiful Soup
- Tensorflow
- Machine Learning Crash Course
- Google Cloud Machine Learning Engine (optional)
- Sanity
The Setup
- Obtain past winning 4d lottery results from Singapore Pools website
- Data prep and feature engineering
- Training the model and hyper-parameter tuning
- Prediction results
Obtain past winning 4d lottery results from Singapore Pools website
This was when I hit my first roadblock.
If you head over to Singapore Pools 4d Results page, you'll find that they only provide 4d results for the past three years.
With a bit of Google-Fu, I managed to locate a page within their website to check winning numbers for the past 20 years.
The steps taken to extract the data were as follow:
- Download PhantomJS and Chrome Webdriver.
- Set up a virtual environment.
- Install Selenium and BeautifulSoup.
- Create the scraper in Python.
- Save the results to Excel for data prep.
- A whole load of patience.

Data prep and feature engineering
My initial thoughts were that I had very little to work with.
The two features(Number, Date) were not sufficient to train the model accurately.
...
1001 . Sat, 12 Jan 2019 . Consolation Prize
1001 . Sun, 06 Sep 2015 . Starter Prize
1001 . Sat, 06 Sep 2014 . Starter Prize
...It turns out that we could actually derive meaningful metrics with a little feature engineering elbow grease.
...
0001 . 3 . 15 . 320 . 3 . 47 . 11 . 2000 . 668 . 21 . 1 . 6697 . 957 . 19 . 0 . 0 . 0 . 0 . 1 . 5
0010 . 6 . 14 . 257 . 3 . 37 . 9 . 2002 . 942 . 30 . 2 . 6029 . 861 . 17 . 0 . 0 . 0 . 0 . 1 . 5
9800 . 3 . 13 . 103 . 3 . 16 . 4 . 2005 . 130 . 4 . 0 . 5087 . 727 . 14 . 0 . 0 . 0 . 0 . 1 . 5
...Why not create binary vectors for numbers 0000 to 9999?
That would be an exteremely bad idea. The computation resources required for such intensive task are expensive. This form of data representation is extremely inefficient.
Instead, we should approach the problem using sparse representation.
The data is split between 70% (Training Data), 25% (Test Data) and 5% (Evaluation Data).
Training the model and hyper-parameter tuning
The model trained for 100 times using Gradient Descent and Adam optimisers.
Each round took between 15 to 25 minutes on my MacBook Pro.
I could leverage on Google's Cloud Machine Learning Engine to cut my training time by half but I'm a cheapskate.
These were the ideal hyper-parameter settings after 100 tests:
| ID | Optimizer | Learning Rate | Epochs | Batch Size | Dense Layers | L2 Regularization | Dropout |
|---|---|---|---|---|---|---|---|
| 1 | Adam | 0.001 | 301 | 16 | 16 | 0.001 | 0 |
| 2 | Adam | 0.0001 | 301 | 16 | 16 | 0.001 | 0 |
| 3 | Adam | 0.0005 | 301 | 16 | 16 | 0.001 | 0 |
| 4 | Gradient Descent | 0.001 | 301 | 16 | 16 | 0.001 | 0 |
| 5 | Gradient Descent | 0.0001 | 301 | 16 | 16 | 0.001 | 0 |
| 6 | Gradient Descent | 0.0005 | 301 | 16 | 16 | 0.001 | 0 |
| 7 | Adam | 0.001 | 301 | 16 | 16 | 0 | 0.5 |
| 8 | Adam | 0.0001 | 301 | 16 | 16 | 0 | 0.5 |
| 9 | Adam | 0.0005 | 301 | 16 | 16 | 0 | 0.5 |
| 10 | Gradient Descent | 0.001 | 301 | 16 | 16 | 0 | 0.5 |
| 11 | Gradient Descent | 0.0001 | 301 | 16 | 16 | 0 | 0.5 |
| 12 | Gradient Descent | 0.0005 | 301 | 16 | 16 | 0 | 0.5 |
The results based on ideal hyper-parameter settings.
| Training Metrics | Results |
|---|---|
 |
Epoch 000: Loss: 729.569, Accuracy: 33.531% |
 Overfitting |
Epoch 000: Loss: 81.530, Accuracy: 39.018% |
 Overfitting |
Epoch 000: Loss: 45.983, Accuracy: 40.437% |
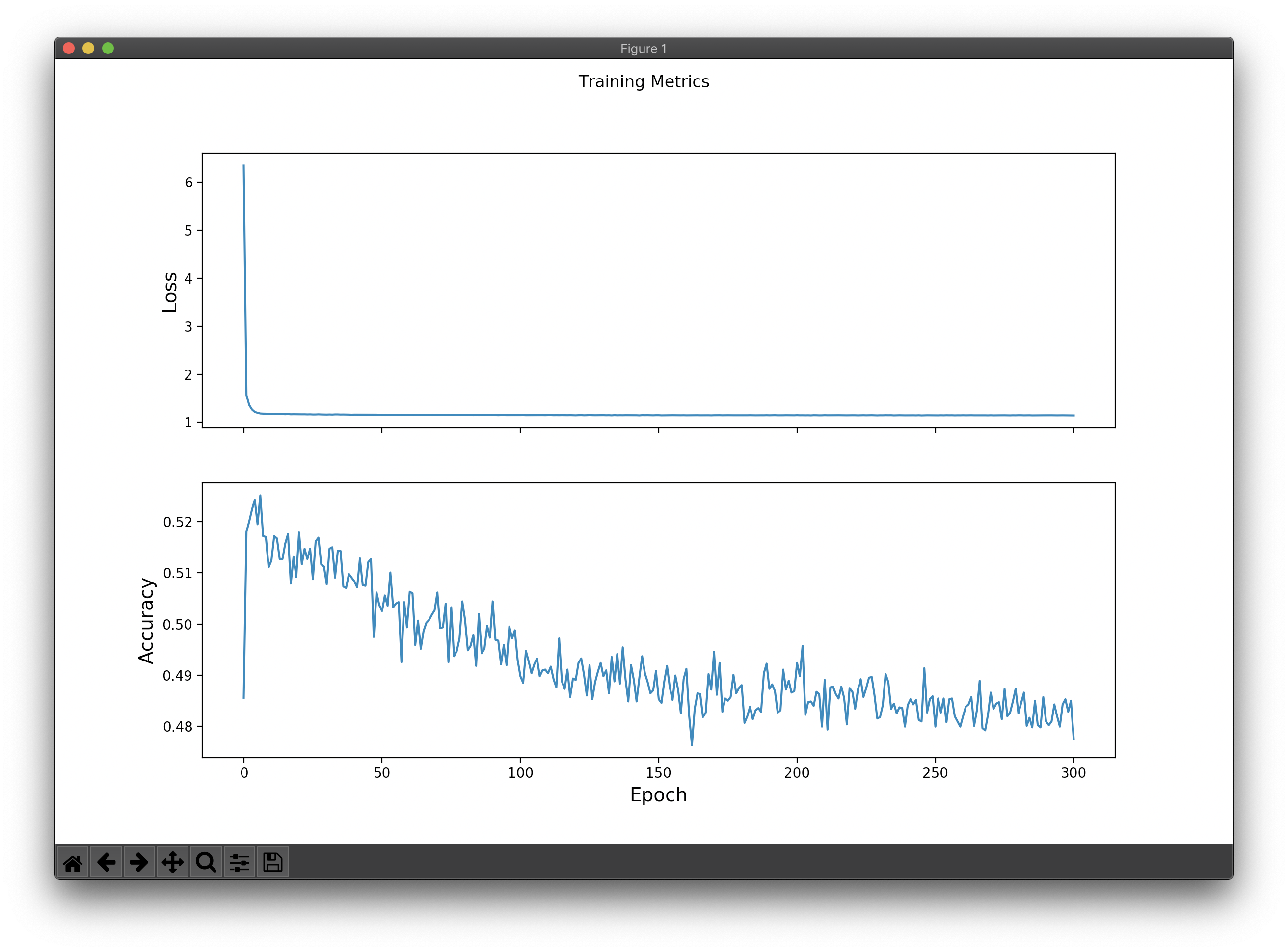 |
Epoch 000: Loss: 6.345, Accuracy: 48.559% |
 |
Epoch 000: Loss: 3.950, Accuracy: 44.375% |
 |
Epoch 000: Loss: 19.132, Accuracy: 43.984% |
 |
Epoch 000: Loss: 143.438, Accuracy: 36.137% |
 Overfitting |
Epoch 000: Loss: 301.922, Accuracy: 29.390% |
 |
Epoch 000: Loss: 60.548, Accuracy: 35.370% |
 |
Epoch 000: Loss: 8.623, Accuracy: 44.781% |
 |
Epoch 000: Loss: 10.269, Accuracy: 44.650% |
 |
|
| Training Metrics |
|---|
|
Epoch 000: Loss: 729.569, Accuracy: 33.531% |
Overfitting Epoch 000: Loss: 81.530, Accuracy: 39.018% |
Overfitting Epoch 000: Loss: 45.983, Accuracy: 40.437% |
|
Epoch 000: Loss: 6.345, Accuracy: 48.559% |
|
Epoch 000: Loss: 3.950, Accuracy: 44.375% |
|
Epoch 000: Loss: 19.132, Accuracy: 43.984% |
|
Epoch 000: Loss: 143.438, Accuracy: 36.137% |
Overfitting Epoch 000: Loss: 301.922, Accuracy: 29.390% |
|
Epoch 000: Loss: 60.548, Accuracy: 35.370% |
|
Epoch 000: Loss: 8.623, Accuracy: 44.781% |
|
Epoch 000: Loss: 10.269, Accuracy: 44.650% |
|
Epoch 000: Loss: 4.455, Accuracy: 44.737% |
A few take-aways based on the results.
- In general, the Adam optimisation algorithm performed much better than Gradient Descent.
- Accuracy was most affected by the learning rate as compared to the rest of the parameters.
- Adding L2 regularization and Dropout yielded minimal improvements.
Prediction results
The moment we've all been waiting for!
Based on the trained model, we predict the probability for a set of numbers from the evaluation data.
0067 . Wed, 14 Nov 2018 . Third Prize
0831 . Sun, 06 Oct 2013 . Second Prize
0965 . Wed, 31 Jul 2013 . Starter Prize| Version | Predictions |
|---|---|
| 1 | Example 0 prediction: first_prize (29.9%) |
| Example 1 prediction: second_prize ( 0.2%) | |
| Example 2 prediction: starter_prize ( 0.5%) | |
| 2 | Example 0 prediction: third_prize ( 0.0%) |
| Example 1 prediction: second_prize ( 0.1%) | |
| Example 2 prediction: starter_prize ( 0.0%) | |
| 3 | Example 0 prediction: third_prize ( 0.0%) |
| Example 1 prediction: second_prize ( 0.0%) | |
| Example 2 prediction: starter_prize ( 0.0%) | |
| 4 | Example 0 prediction: consolation_prize (41.5%) |
| Example 1 prediction: consolation_prize (41.0%) | |
| Example 2 prediction: consolation_prize (41.4%) | |
| 5 | Example 0 prediction: starter_prize ( 4.6%) |
| Example 1 prediction: starter_prize ( 4.6%) | |
| Example 2 prediction: starter_prize ( 4.6%) | |
| 6 | Example 0 prediction: starter_prize ( 4.5%) |
| Example 1 prediction: starter_prize ( 4.5%) | |
| Example 2 prediction: starter_prize ( 4.5%) | |
| 7 | Example 0 prediction: third_prize ( 4.3%) |
| Example 1 prediction: second_prize (11.7%) | |
| Example 2 prediction: starter_prize ( 0.1%) | |
| 8 | Example 0 prediction: third_prize ( 0.0%) |
| Example 1 prediction: second_prize ( 0.3%) | |
| Example 2 prediction: starter_prize ( 0.0%) | |
| 9 | Example 0 prediction: starter_prize ( 4.6%) |
| Example 1 prediction: starter_prize ( 4.6%) | |
| Example 2 prediction: starter_prize ( 4.6%) | |
| 10 | Example 0 prediction: starter_prize ( 6.0%) |
| Example 1 prediction: starter_prize ( 6.1%) | |
| Example 2 prediction: starter_prize ( 6.0%) | |
| 11 | Example 0 prediction: starter_prize ( 4.6%) |
| Example 1 prediction: starter_prize ( 4.6%) | |
| Example 2 prediction: starter_prize ( 4.6%) | |
| 12 | Example 0 prediction: starter_prize ( 4.6%) |
| Example 1 prediction: starter_prize ( 4.6%) | |
| Example 2 prediction: starter_prize ( 4.6%) |
As you can see, the results were unsurprising.
- None of the predictions was satisfactory.
- The probability was low even though the corresponding test set accuracy was high.
- Models that overfit produced 0% or close to 0% probability as expected.
Conclusion
If you do a quick google search for the terms "4d prediction singapore", you’ll find no shortage of 4d prediction websites.
These predictions are often served with a healthy dose of snake oil.
The draw process, engineered by Singapore Pools includes numerous variables to deter fraud. Trying to predict winning combinations would be a fool's errand.
To make an almost accurate prediction, you have to factor in draw machine configurations and draw ball weights, as well as unseen elements like the force of the jet air, atmospheric noise and gravitational pull.
Punters believe that there are patterns to lottery numbers which can help increase the probability of winning.
As with all things in life, you will start to see patterns by over-analysing any situation.
I have no answers as to how Ms Foyce predicted her winning numbers but it is most likely not through a magical black box algorithm machine.
As many have said, she could have bought the tickets in bulk and posted the winning combinations after the results were announced.
There are many ways to achieve internet notoriety you know?
Fun fact: Your money is better spent elsewhere.
Wealth gained hastily will dwindle, but whoever gathers little by little will increase it. - (Proverbs 13:11-13)
Disclaimer: I am not a data scientist, neither am I trained in the field of machine learning. Several assumptions were made while training the models. If you are a data scientist, please feel free to chime in on the comments section.


